Do they think it’s true? Automatic Rumour Stance Classification.
This post describes the task and the winning system of SemEval-2017 Task 8 RumourEval A Stance Classification, where teams had to create systems that would classify tweets discussing different rumours as either supporting, denying, questioning the truthfulness of the rumour or just commenting on it. Teams had access to the complete Twitter conversations and were able to reconstruct their structure. The winning system submitted by team Turing used LSTM recurrent neural networks to model linear sequences of tweets represented as averages of their word vectors concatenated with extra features such as punctuation, lexicon and relation to other tweets.
What’s the problem?
Did a giant beach ball bounce on the streets of London? Did a shark swim around houses in a flooded New Jersey street?

(YES, this actually happened!)

(NO, this was a false rumour!)
(Images and veracity information are taken from the Verification Handbook)
False information circulating on social media are not just for entertainment as the shark example above but also presents many risks since social media is used as a source of news by many users. For example, the financial risk of false information has been in the spotlight with news of fraud charges against a British stock trader who in 2013 tweeted false statements about companies to manipulate share prices, causing shareholder loss of $1.6m. Information on social media spreads and grows in volume rapidly making the task of verifying it very complex and impossible to carry out manually in real time.
This makes Machine Learning researchers and big IT companies like Facebook and Google have significant interest in creating automated fact-checking systems to prevent the spread of misinformation through Social Media.
Several competitions having been set up to help tackle this problem from different prospectives. Related competitions include:
- RumourEval http://alt.qcri.org/semeval2017/task8/
- Fake News Challenge http://www.fakenewschallenge.org
- Discovertext Fake News Detection: A Twitter data challenge for students
http://discovertext.com/2016/12/28/fake-news-detection-a-twitter-data-challenge-for-students/
This post discusses the RumourEval competition and describes the winning system.
Competition
SemEval (short for Semantic Evaluation) is an annual challenge that consists of a range of various shared tasks on computational semantic analysis. Tasks may include semantic comparison for words and texts; detecting sentiment, humour or truth and parsing semantic structures. The systems developed by all teams are published in the SemEval workshop proceedings. The workshop is usually collocated with one of the major conferences in Natural Language Processing.
RumourEval is Task 8 for the SemEval-2017 challenge. RumourEval addresses the problem of rumour propagation in social media by setting up two subtasks:
- Subtask A is “Rumour Stance Classification” aims to classify the attitude of tweets towards the truthfulness of rumours they are discussing as either Supporting, Questioning, Denying or Commenting (hence the name SDQC).
- The goal of Subtask B “Veracity prediction” is to identify whether a given rumour is True or False.
Dataset
Events
The organisers of the task provided a dataset of tweets discussing rumours emerging around breaking news. The events covered include the shooting in Charlie Hebdo, the crash of a Germanwings plane, the Sydney hostage crisis, the Ferguson unrest, the shooting in Ottawa, rumours about Putin going missing and Essien having Ebola.
The training set was made public in January 2016. For this task organisers built a new testing set which included a mix of conversation threads from different events. Some events overlap with events from training set, and also two new ‘events’ were introduced:
a rumour spread that Youtuber Marina Joyce had been kidnapped and rumours of Hillary Clinton’s health condition during the US election campaign, saying that she was unfit, e.g. having pneumonia.
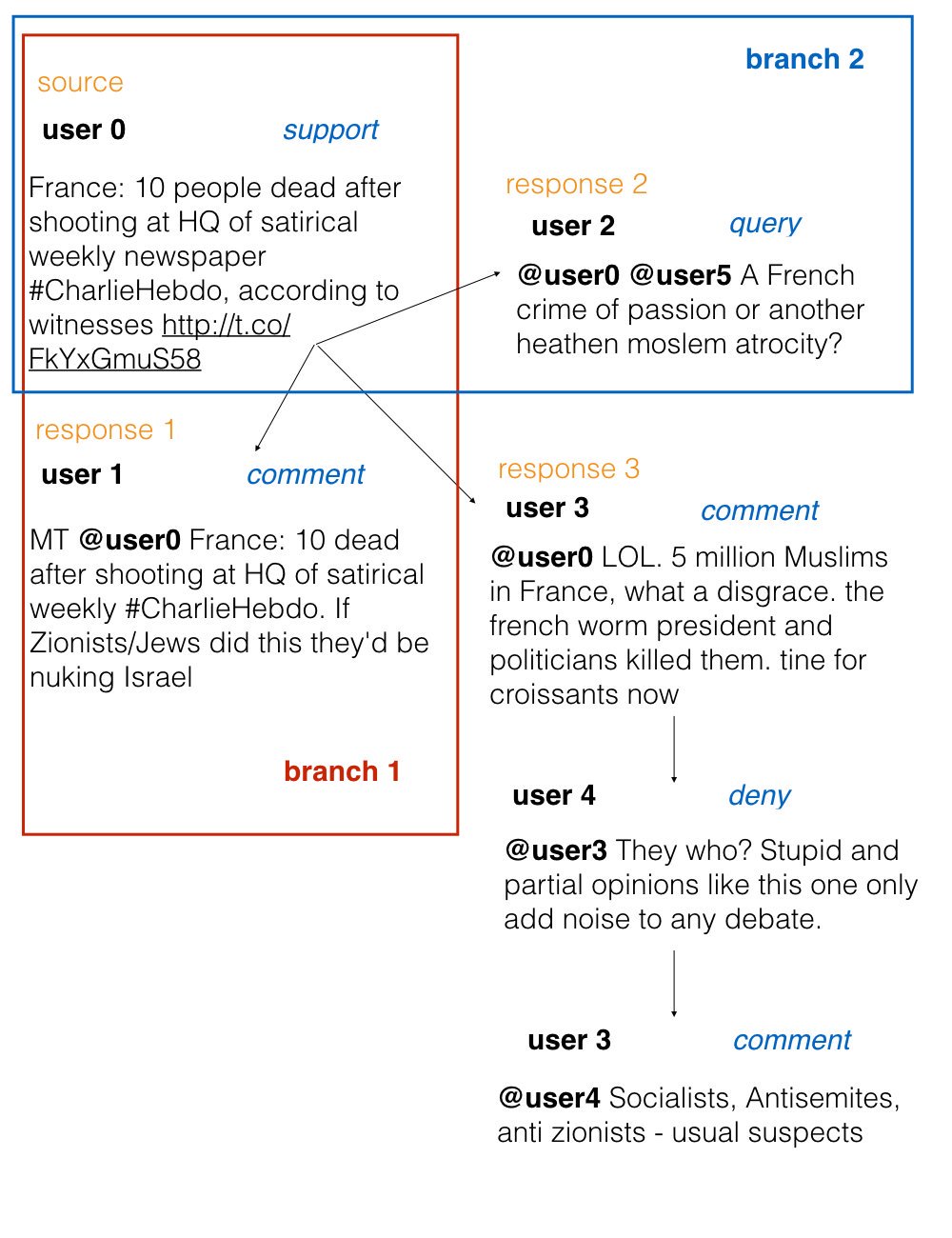
The image below shows an example of the conversation from the dataset:
Size and structure
The dataset contains 297 conversation threads composed of 4519 tweets.
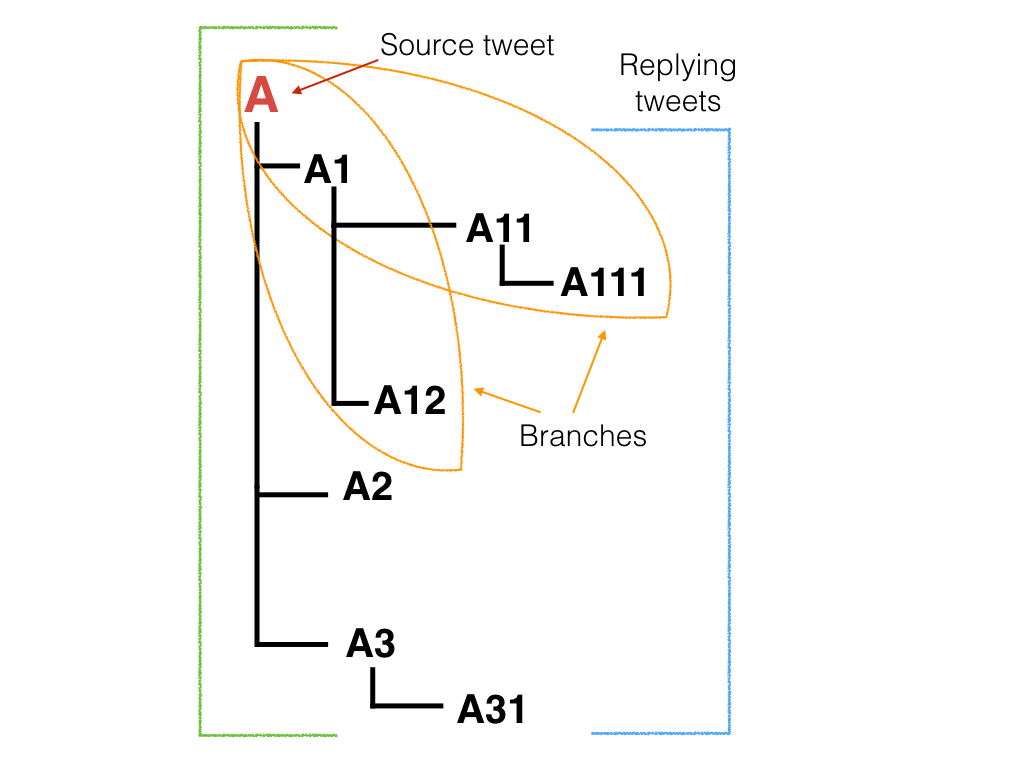
A thread includes a source tweet and all consequent responses forming a tree-like structure. A source tweet is usually tagged as Supporting because it conveys the essence of the rumour in question.
Class imbalance
There is significant class imbalance in the dataset towards the Commenting class (66 %), which does not add any information towards verification of the story, whereas Denying (8%) and Questioning (8%) classes are under-represented. A tendency to support or implicitly support a rumour (rather than questioning or denying it) turns out to be an aspect of people’s reaction to early reports on news breaking events, according to the analysis by Zubiaga et al. in Analysing How People Orient to and Spread Rumours in Social Media by Looking at Conversational Threads.
Why perform rumour stance classification?
A number of studies by different groups of researchers have shown that rumours which are later proven to be False tend to attract significantly more scepticism, (i.e. contain more Denying and Questioning posts) than the ones that are confirmed as True.
(you can check relevant papers by following these links: Mendoza et al., 2010; Procter et al., 2013; Derczynski et al., 2014; Zubiaga et al., 2016 )
Therefore rumour stance classification is viewed as an important step towards verification by exploring the patterns of support and denial among users discussing the rumours.
Why stance classification is a sequential task?
It makes sense to see stance classification as sequential task because the attitude towards the rumour for a user joining the discussion or making a new post will quite likely depend on what he/she sees earlier on in the conversation (or what they themselves has posted earlier).
Moreover, there have been a couple of studies on stance classification by Zubiaga et al. and Lukasik et al., which show that sequential approaches outperform those that consider tweets in isolation.
Our approach
We have entered the competition as team Turing composed of researchers from the University of Warwick and the Alan Turing Institute (Elena Kochkina and Maria Liakata) in collaboration with University College London (Isabelle Augenstein).
Knowing about the success of models utilising conversation structure, we decided to follow a sequential approach that had not been used in previous work.
Overview
Our final system is called branch-LSTM as it uses LSTM layers to model the linear branches of a conversation (see the scheme below). The input to the model at each time step is a representation of a tweet as an average of word vectors (300d Google News word2vec) concatenated with a set of extra features. Extra features include special characters for tweets, punctuation, the presence of links, relation to other tweets, content length (a more detailed feature description can be found here).
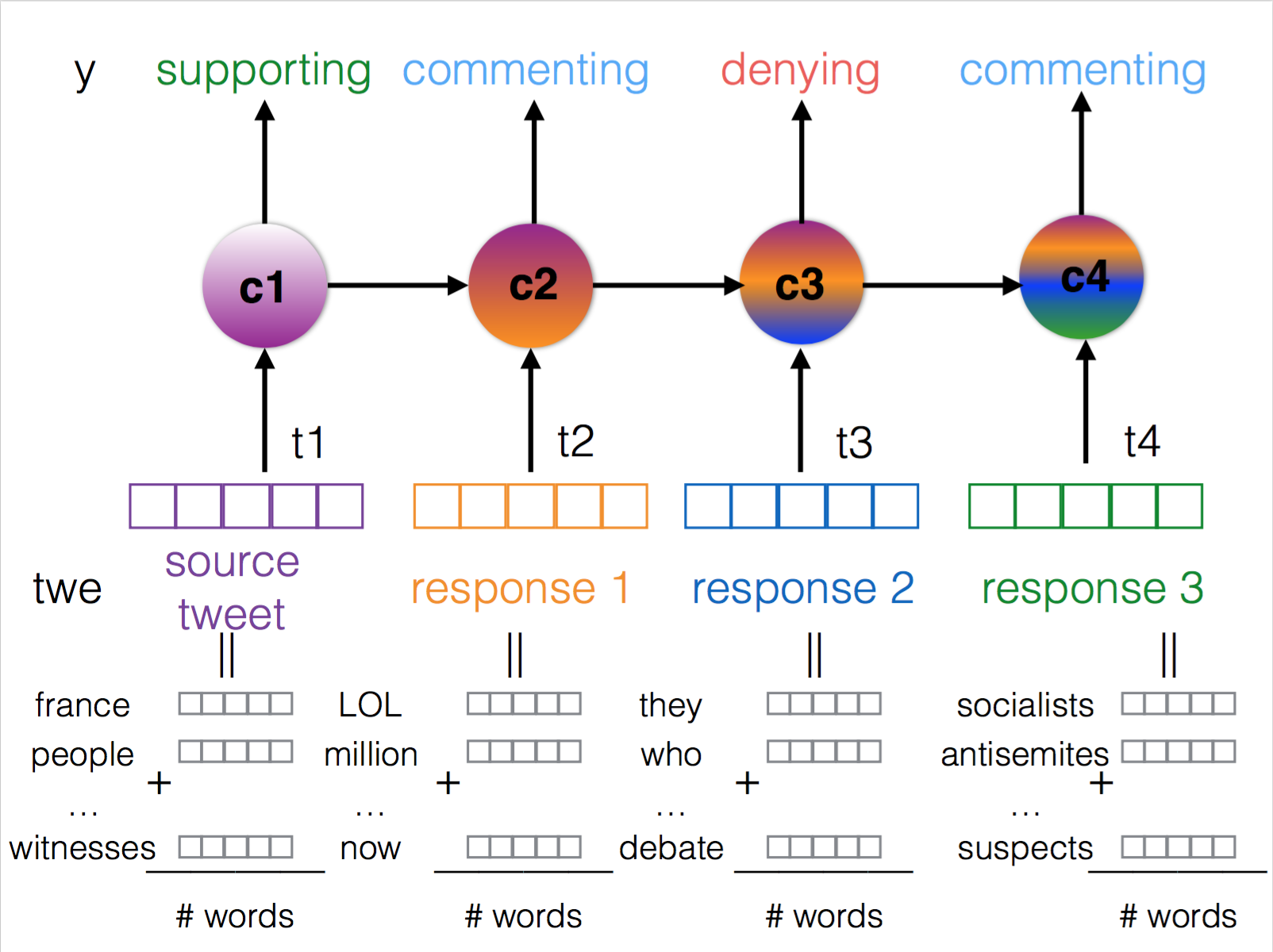
Technical details
The output of 2 LSTM layers of size 200 is put through a 20% dropout, 2 dense layer of size 500 with ReLU activations and a 50% dropout layer. The final predicted class probabilities are the output of a softmax layer. The model is trained for 100 epochs with mini-batch size 64 and learning rate 0.0003 using categorical cross entropy loss and adam optimizer. These hyper parameters were found using the Tree of Parzen Estimators search.
Results and Discussion
The evaluation metric of the competition was the accuracy score ( ranging from 0 to 1, where 1 means a model’s predictions are always correct). Our model achieves 78,4% accuracy on the test set, which allowed it to win the RumourEval competition. Results achieved by other teams are published here.
Accuracy gives equal weight to predictions from all classes and is unable to account for the class imbalance in the dataset. The metric that is able to account for such class imbalance is macro-averaged F1-score (also ranging from 0 to 1, where 1 means a model’s predictions are always correct).
The F1-score of our model is 0.434 on the test set as the model is affected by class imbalance and tends to make a lot of predictions in favour of the majority class. The model does not predict any of the instances as Denying, the smallest class, which is however very important for further rumour verification. The model achieves good results at identifying the Supporting class by labelling all source tweets as Supporting, because this is usually the case in the dataset. The models that consider tweets in isolation would not have been able to pick out this feature without contextual information.
Also, it is worth mentioning that the size of the dataset (4519 tweets) is rather small for deep learning models, and certainly the system would benefit from mitigating the problem of class imbalance as well as from a larger dataset.
What next?
Did we nail it? Well, not yet, but certainly made a step in the right direction.
There is a lot to be explored in the areas of stance classification and rumour verification such as more complex tree-like conversation structures and incorporating background knowledge.
Even though there is a lot of scepticism towards the possibility of automatic rumour verification, it is certainly an important topic to work on and tackling it from different angles and through splitting the larger task into sub-tasks seems like a sensible approach that would lead to a strong system; shared tasks and challenges certainly make a contribution towards it.




RumourEval: bringing veracity checking to the community Mental Health and Social Media
Comments are currently closed.